
TerraCodec
Collection
Compressing Optical Earth Observation Data • 6 items • Updated
Neural Compression for Earth Observation
TerraCodec (TEC) is a family of pretrained neural compression codecs for multispectral Sentinel-2 satellite imagery. The models compress optical Earth observation data using learned latent representations and entropy coding.
Compared to classical codecs such as JPEG2000 or WebP, TerraCodec achieves 3–10× higher compression at comparable reconstruction quality on multispectral satellite imagery. Temporal models further improve compression by exploiting redundancy across seasonal image sequences of satellite imagery.

| Model | Available Checkpoints | Description |
|---|---|---|
terracodec_v1_fp_s2l2a |
λ = 0.5, 2, 10, 40, 200 | Factorized-prior image codec. Smallest model and strong baseline for multispectral image compression. |
terracodec_v1_elic_s2l2a |
λ = 0.5, 2, 10, 40, 200 | Enhanced entropy model with spatial and channel context for improved rate–distortion performance. |
terracodec_v1_tt_s2l2a |
λ = 0.4, 1, 5, 20, 100, 200, 700 | Temporal Transformer codec modeling redundancy across seasonal image sequences. |
flextec_v1_s2l2a |
Single checkpoint (quality = 1–16) | Flexible-rate temporal codec. One model supports multiple compression levels via token-based quality settings. |
Lower λ / quality → higher compression
Higher λ / quality → higher reconstruction quality
This repository contains the FlexTEC variant of TerraCodec.
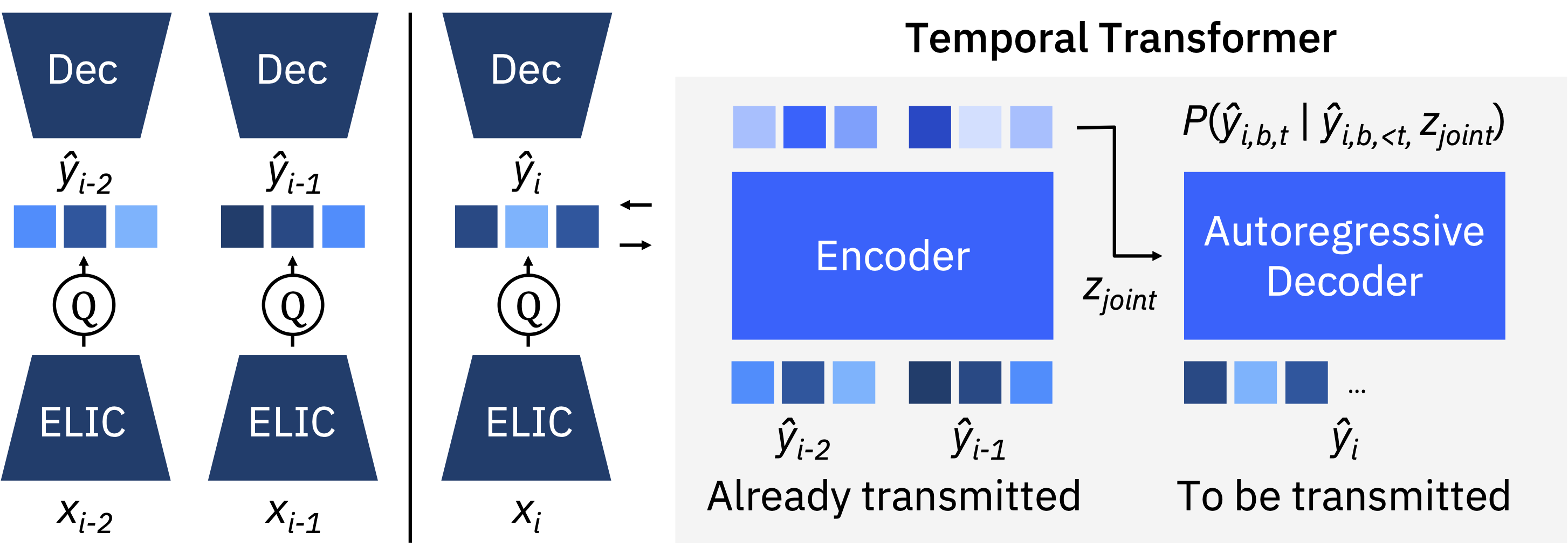
FlexTEC builds on the TerraCodec Temporal Transformer (TEC-TT) architecture and introduces flexible-rate compression within a single model.
Instead of training separate checkpoints for different rate–distortion settings, FlexTEC supports multiple compression levels through Latent Repacking and missing token prediction. During training, tokens are randomly masked to simulate different compression budgets. At inference time, the number of transmitted tokens controls the compression level: fewer tokens yield higher compression, while more tokens improve reconstruction quality.
See the paper for additional architectural and training details.
| Codec type | Expected shape | Example |
|---|---|---|
| Image codecs | [B, C, H, W] |
[1, 12, 256, 256] |
| Temporal codecs | [B, T, C, H, W] |
[1, 4, 12, 256, 256] |
Models were trained on SSL4EO-S12 v1.1.
Inputs should be standardized per spectral band using dataset statistics. For S2L2A:
mean = torch.tensor([793.243, 924.863, 1184.553, 1340.936, 1671.402, 2240.082, 2468.412, 2563.243, 2627.704, 2711.071, 2416.714, 1849.625])
std = torch.tensor([1160.144, 1201.092, 1219.943, 1397.225, 1400.035, 1373.136, 1429.170, 1485.025, 1447.836, 1652.703, 1471.002, 1365.307])
Install TerraCodec:
pip install terracodec
Load pretrained models and set quality level:
from terracodec import flextec_v1_s2l2a
model = flextec_v1_s2l2a(pretrained=True)
# Forward pass (fast reconstruction, no bitstream)
reconstruction, _ = model(sequence, quality=8)
# True compression
compressed = model.compress(sequence, quality=8)
reconstruction = model.decompress(**compressed)
If you have questions, encounter issues or want to discuss improvements:
GitHub repository: https://github.com/IBM/TerraCodec
If you use TerraCodec in your research, please cite:
@article{terracodec2025,
title = {TerraCodec: Compressing Optical Earth Observation Data},
author = {Costa Watanabe, Julen and Wittmann, Isabelle and Blumenstiel, Benedikt and Schindler, Konrad},
journal = {arXiv preprint arXiv:2510.12670},
year = {2025}
}