
SpatialStack: Layered Geometry-Language Fusion for 3D VLM Spatial Reasoning
Paper • 2603.27437 • Published
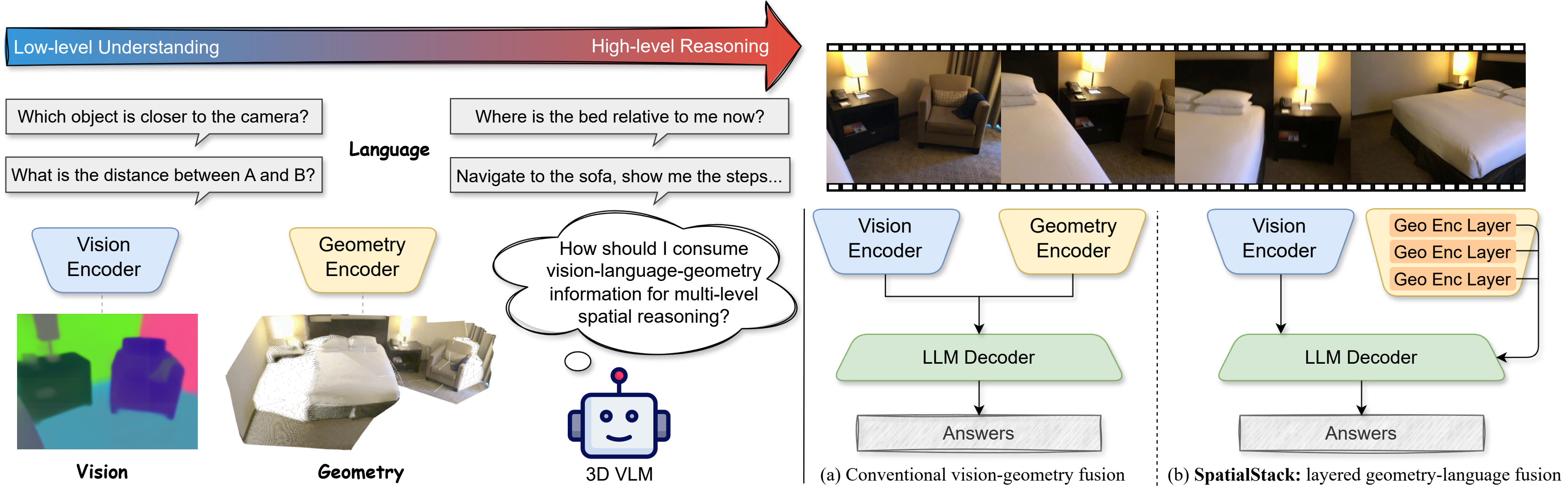
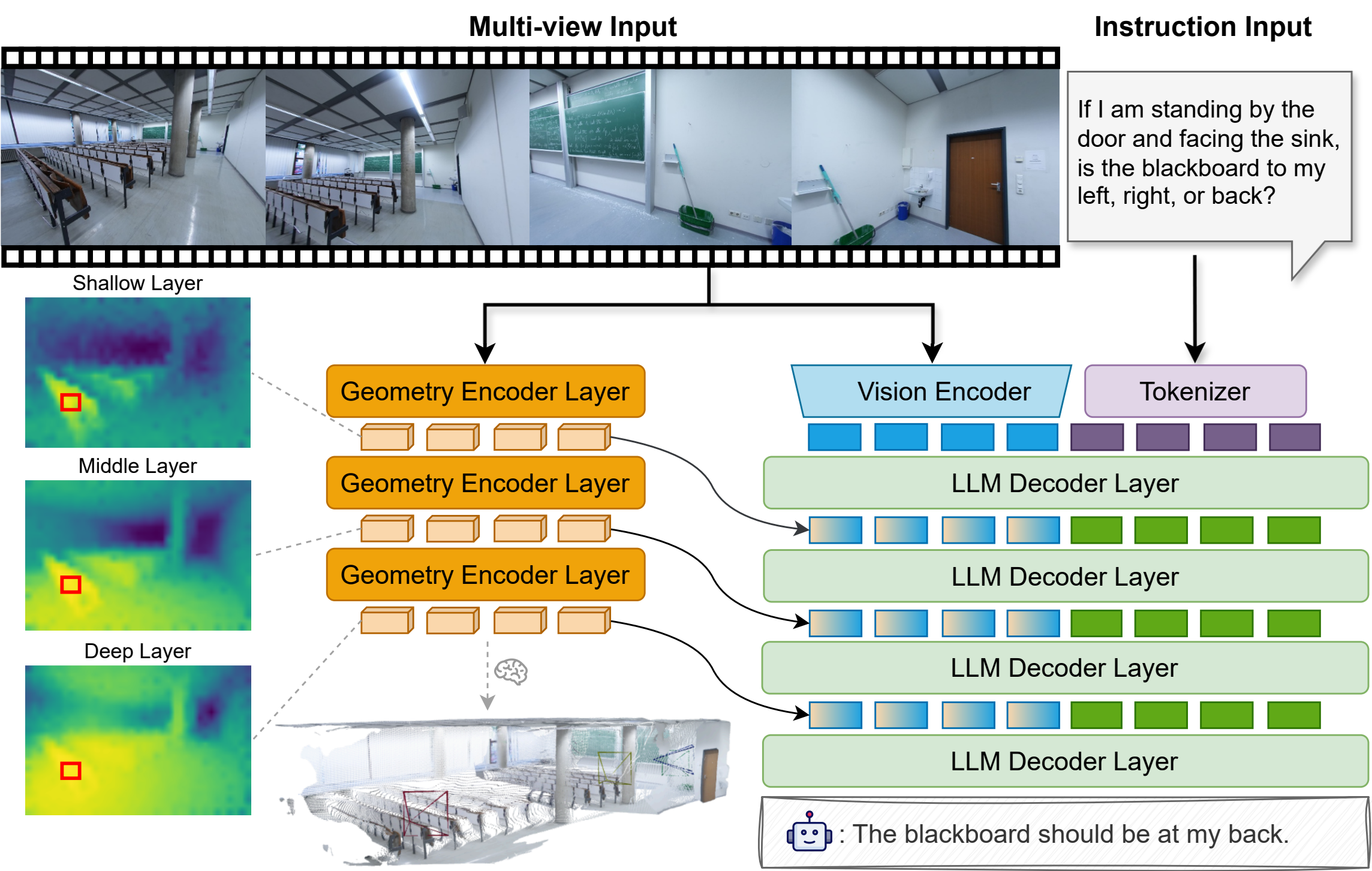
SpatialStack-Qwen3.5-4B is a geometry-augmented vision-language model designed for 3D spatial reasoning. It extends Qwen3.5-4B with a parallel VGGT-1B geometry stream, using a novel layered geometry-language fusion mechanism that progressively aligns multi-level geometric and language features across model layers.
Geometry features from encoder layers [11, 17, 23] are projected and injected into decoder layers [0, 1, 2], preserving both fine local structure and higher-level spatial context.
| Component | Detail |
| Base Model | Qwen/Qwen3.5-4B |
| Geometry Encoder | facebook/VGGT-1B |
| Encoder Layers | [11, 17, 23] |
| Fusion Layers | [0, 1, 2] |
| Fusion Method | DeepStack Language-Add |
| Geometry Merger | MLP |
| Precision | bfloat16 |
| Benchmark | Metric | Score |
|---|---|---|
| VSI-Bench | Average | 67.5 |
| CV-Bench | Average | 85.5 |
| CV-Bench | 3D | 92.2 |
Results from the SpatialStack project page and paper.
git clone https://github.com/jzh15/SpatialStack.git
cd SpatialStack
pip install -e . --no-deps
For full environment setup (PyTorch, flash_attn, Qwen3.5 dependencies), see the repo README.
python scripts/inference/infer.py \
--model-path Journey9ni/SpatialStack-Qwen3.5-4B \
--image assets/sofas.jpg \
--prompt "Describe this scene in a few complete sentences." \
--disable-thinking \
--max-new-tokens 128
MODEL_PATH=Journey9ni/SpatialStack-Qwen3.5-4B \
MODEL_IMPL=qwen3_5 \
MODEL_ARGS_BASE="pretrained=Journey9ni/SpatialStack-Qwen3.5-4B,use_flash_attention_2=true,max_num_frames=32,max_length=12800,geometry_encoder_path=facebook/VGGT-1B,disable_thinking=true" \
OUTPUT_ROOT=logs/eval/spatialstack_qwen35_4b \
BENCHMARKS="vsibench" \
bash scripts/evaluation/eval.sh
@article{zhang2026spatialstack,
title={SpatialStack: Layered Geometry-Language Fusion for 3D VLM Spatial Reasoning},
author={Zhang, Jiang and Zhou, Shijie and Liu, Bangya and Kadambi, Achuta and Fan, Zhiwen},
journal={arXiv preprint arXiv:2603.27437},
year={2026}
}